Interior Point Methods for Solving Linear Programs
- These notes are based on my semester research project in the Theoretical Computer Science Lab at EPFL, where I was supervised by Prof. Kapralov and Kshiteej Sheth.
- Having an idea of what Linear Programs are and Convex Optimization is recommended before reading.
1. Introduction & Problem Statement
Interior-Point Methods are approximation algorithms that solve linear programs. Seen as a framework, it is until now the fastest known algorithm for solving the famous maximum-flow problem on graphs, and although it has many numerical stability problems in practice, it's the current best framework for optimizing (with high accuracy) general convex functions in both theory and practice.
These notes first present the general framework of Interior-Point Methods and how it works, and then the concept of barriers is formalized to present the Lee-Sidford barrier, which is used to achieve runtime improvements. The notes will focus on understanding the theoretical concepts of the method rather than focusing on the details of the runtime. The concepts are in my opinion super interesting and very smart!
Given primal variable , objective with and constraints with and , our goal is to solve
approximately up to -error. This is our contrained optimization problem, and the constraints define a convex subset of which we call the polytope.
2. Framework Intuition
Unlike other methods for solving linear programs like the Simplex Method that stay on the border of the polytope, in the Interior-Point method we want to start inside the polytope and away from the border, and slowly move towards the border to always work with a feasible point.
2.1 How We Do It
To stay away from the border we massage our constrained optimization problem into an unconstrained one. We introduce a convex function that we will add in our objective, such that as we get closer to the border, the value of the function explodes. This enables to penalize when we arrive near the border and we don't go out of the polytope. Such a function is called a barrier, and one simple example of such a function is the log barrier , where are the columns of . We can now add to our objective function the term , where is a scalar. ensures that we stay in the feasible region, and acts as a regularization term such that when is small, we are close enough to the original problem that we can get a satisfactory approximation.
The modified problem statement is now
and we will look at solving this (form of) problem now. Note that this is a set of problems, because the problem changes as changes. The set of optimum points of is called the central path. And as said before, intuitively, when , where is the optimum of . So the idea of the algorithm is that we will follow the central path going in the direction of (thus decreasing ).
The algorithm proceeds iteratively as follows:
- Initialization: start at , find an initial feasible point "close enough" to .
- At each iteration, move "close enough" to for current , and then decrease multiplicatively: ,
- return once (achieved -error)
How we measure "closeness" will be defined more formally later. Achieving -error is dependent on how small is.
From this general intuition, two main questions arise:
- How close should be to at each iteration ? THis will control the per-iteration cost.
- How much can we decrease at each iteration ? This will control the number of iterations.
2.2 Some More Intuition
Before going to the next section, I give more detail to the above two questions. Theorems and lemmas defined later will clarify this part, so if things don't get clearer while reading, you can continue to the next parts.
There's a region that has to lie into to be able to move closer to . If is not in this region, it might be impossible (or too costly) to later move it closer to . So when changing to , we change the target to and thus we change the region we're looking at: might be in the region of but it might not be in the region of . That's why we first move closer to , and because of geometric dependecies between and , now is also close enough so that it is in the region of . Also, if we decrease too fast ( too high) then we might pay too much in moving closer to , because the region of is even farther away.
These are subtleties that will be handled by lemmas in the more formal sections. But for now here are the two more detailed questions:
- At each iteration, how close should be to to lie inside the region of ? This will control the per-iteratin cost.
- How much can we decrease at each iteration ? This will control the number of iterations.
Finally, recall that we always want to be close to because as we decrease , aproaches .
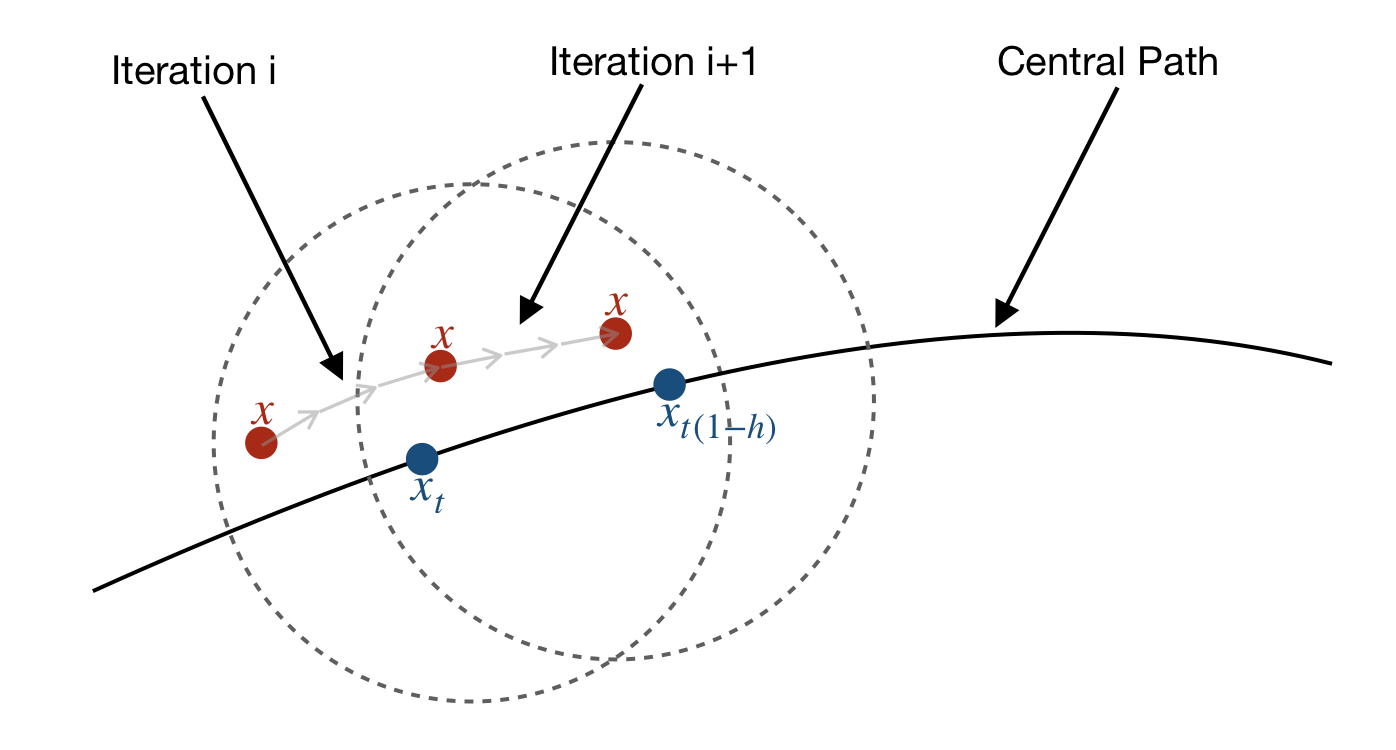
The above image illustrates the process of following the central path. The dotted circles are the regions of and . The per-iteration cost is represented by the grey arrows.
3. General Framework
As mentioned before, we start by softening
where is a subset of into
where and is a convex function such that as . We call a barrier function for .
Definition 1: The central path is defined as
The framework is as follows:
- Find a feasible close to
- While is not small enough
- Move closer to
- ,
The goal of IPMs is to start with a point in the central path, and following it until we get a good approximation of the original problem. We do not present how to get the initial point, but there exists multiple methods for getting an initial point efficiently, one of which can be found in Reference 2.
Let's now show that this framework works!
3.1 Newton Step and Distance Measure
To move closer to , we are using Newton steps:
Since Newton's method uses the Hessian and performs better when changes in doesn’t change too much the hessian, we are motivated to make the assumption that the Hessian is Lipschitz (smoothness property). This is why we introduce the definition of self-concordance in the next subsection.
Note that the norm of is called the step size.
To study the performance of a Newton’s iteration, we need to define how we measure the distance of to . Since the smaller the step size, the closer we are to the optimum (because small), we define the distance in terms of the size of the step in the Hessian norm.
Definition 2: Given a positive-definite matrix , define . The distance of to is defined as follows
The inverse hessian norm is used to account for the amount of Newton steps needed for to converge to . This makes sense algorithmically because the algorithm is faster if few Newton steps are made.
Note that is also (this can be derived by simple calculation). We will mainly use this form instead of the one given in the definiton, but I really wanted to point out that the definition comes from a motivation to analyze Newton steps.
Also note that .
3.2 Self-Concordance: Enabling Convergence
Since we're using Newton steps, remember the convenient assumption that the Hessian should be Lipschitz. Let's define more formally what is the smoothness property we want.
Definition 3: A convex function is said to be self-concordant if , , we have
D is the directional derivative of in directions .
Integrating the local inequality that we have from the definition, we get the following inequality, which says that locally the Hessian of a self-concordant function doesn't change too fast:
Lemma 1: Let be a self-concordant function. Then , and s.t. ,
Proof. See Appendix (Self-concordance is necessary to prove this lemma)
When we change , we want the new distance from to be smaller in order to make progress. This is what self-concordance enables. It says that locally, hessian doesn't change too much, so it gives insurance that our Newton step won't diverge or make jumps and stop progressing.
The following lemma uses this, and says that the self-concordance condition on guarantees convergence when we try to move closer to , provided that was already close enough. This lemma is one of the main tools that enables the algorithm to proceed iteratively and converge towards the optimum.
Lemma 2: Let be a self-concordant barrier function. Suppose that . Then, after one Newton step of the form , we have
And moving using the Newton method results in moving closer to .
Proof. See Appendix (Lemma 1. is necessary to prove this lemma)
3.3 Following the Central Path
Now, changing must be done carefully, because we want to be as big as possible (to minimize the number of iterations), while still maintaining our invariant of Lemma 2. The following lemma gives an upper-bound on the amount that can change as we change , and suggests a maximum amount by which can change up to the point that our premise of Lemma 2. still holds in the next iteration.
Lemma 3: Let be a self-concordant barrier function. is updated following . Then we have that
Proof. See Appendix
We can now know how big can be. For this, let's make our framework more quantitative:
- Find a feasible such that
- While is not small enough:
- (this decreases to )
Assume that . Then, according to Lemma 2., after a single Newton step, . To maintain for the next iteration, we want
So we need . Taking to be equal to this value maximizes the change of .
Notice that the amount by which we change depends on . The lower this value, the fewer number of iterations we will have to do. We can now derive the second property of self-concordance, and we can now fully define what is -self-concordance.
Definition 4: Let be a convex subset of . We say that is a -self-concordant barrier on if
for all and (Definition 3.)
for all
3.4 Termination Condition
Finally, it remains to determine how small needs to be to achieve -error. One can upper bound the error by using the duality gap of the problem.
Lemma 4: Let be a -self-concordant barrier on , and let be the optimum of . We have that
Proof. See Appendix
Our is a constant number of iterations close to , so to have there is only needed a constant number more iterations. Hence, to get an -error we can set . We can now give the final version of our framework.
Final IPM framework
- Find a feasible such that
- While :
- (by Lemma 2., )
- ,
With this framework complete we can now state a main IPM theorem regarding performance.
3.5 Main IPM Theorem
Theorem 1: Let be the polytope defined by the constraints of . Given a -self-concordant barrier on , we can solve up to -error in iterations.
Proof. We need to show that we reach -error in Newton steps and updates of .
We start at , and at each iteration we multiply by a factor . Let be the number of iterations. We want
Solving this gives .
Discussion
The performance of the IPM framework we've given depends on , the self-concordance of the barrier function we choose. This sort of modularizes the research on the subject and enables to improve the performance by concentrating on finding a better (smaller ) barrier function.
This is the topic of another note, which concentrates on the Lee-Sidford barrier, the current best barrier function found that is computable.
References
- Y. T. Lee, A. Sidford - Solving Linear Programs with sqrt(rank) linear system solves
- Lecture notes from the famous Yin Tat Lee: CSE 599: Interplay between Convex Optimization and Geometry
Appendix
Proof Lemma 1.
Let with . Then we have that . By self-concordance we have
For , we have . Hence we have . Integrating both on we have
Rearranging it gives
For general , we can obtain
Rearranging gives
Integrating from to gives the result.
Proof Lemma 2.
Lemma 1. shows that
and hence
To bound , we calculate that
For the first term in the bracket, we use Lemma 1. to get that
Therefore we have
Putting it into (**) gives
Using this inequality with (*) gives the result.
Proof Lemma 3.
Taking the norm, using triangle inequality and using that and , we get
Proof Lemma 4.
We state a first lemma that will help us in the proof.
Lemma: Let be a -self-concordant barrier, and let be the polytope defined by the constraints of . Then, for any
Proof. Let where . Then
We also have that
Combining the two, we get
- If , we are done because and our inequality is satisfied.
- If , then is increasing in , because is convex (and look at the monotonicity of depending on the sign of ). Thus .
Furthermore, integrating the inequality , we have that . Thus, and which gives the target inequality.
Now we can use this lemma to prove Lemma 4.
At the optimal of we have . Therefore we have
which completes the proof.